Intro to Artificial Intelligence
AI is understood in everyday language as machines that think and create. Its substantive definition is "if a machine can calculate then it is intelligent." Through the years, we have been pushing the substrantive definition with each new milestone; first it was Chess, then it was Go.
Machine Learning (ML) means automating tasks by providing examples (training data) instead of writing instructions (code).
- Automating a tool to tell you where are the faces in an image
- Or automating a tool that will label the objects in an image
- Or automate the generation of photorealistic faces (www.thispersondoesnotexist.com)
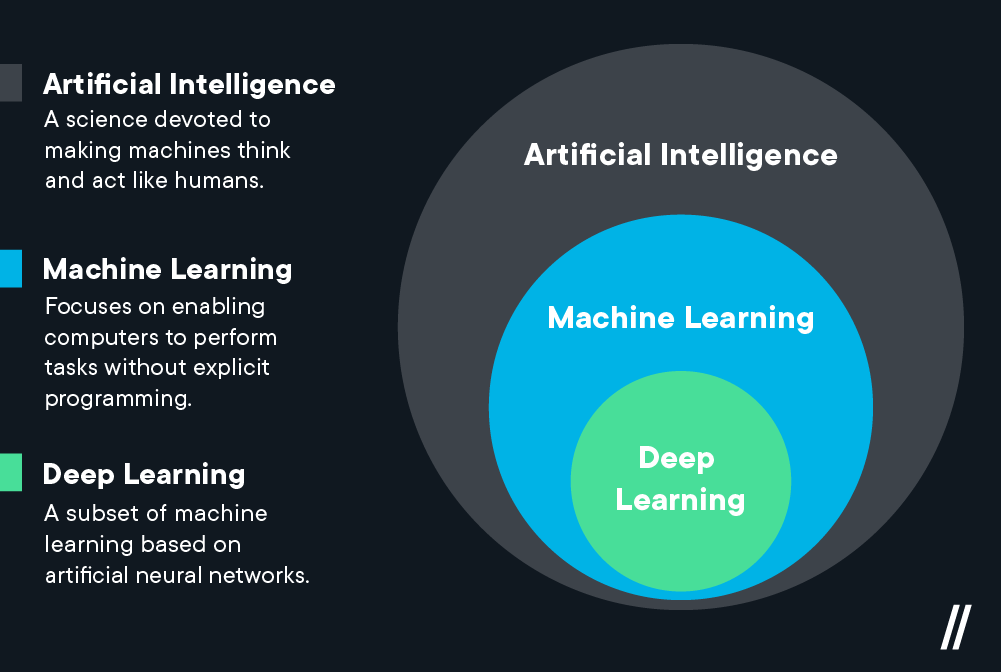
- Deep learning is a type of machine learning, which is a subset of artificial intelligence.
- Machine learning is about computers being able to think and act with less human intervention; deep learning is about computers learning to think using structures modeled on the human brain.
- Machine learning requires less computing power; deep learning typically needs less ongoing human intervention.
- Deep learning can analyze images, videos, and unstructured data in ways machine learning can’t easily do.
Neural Net
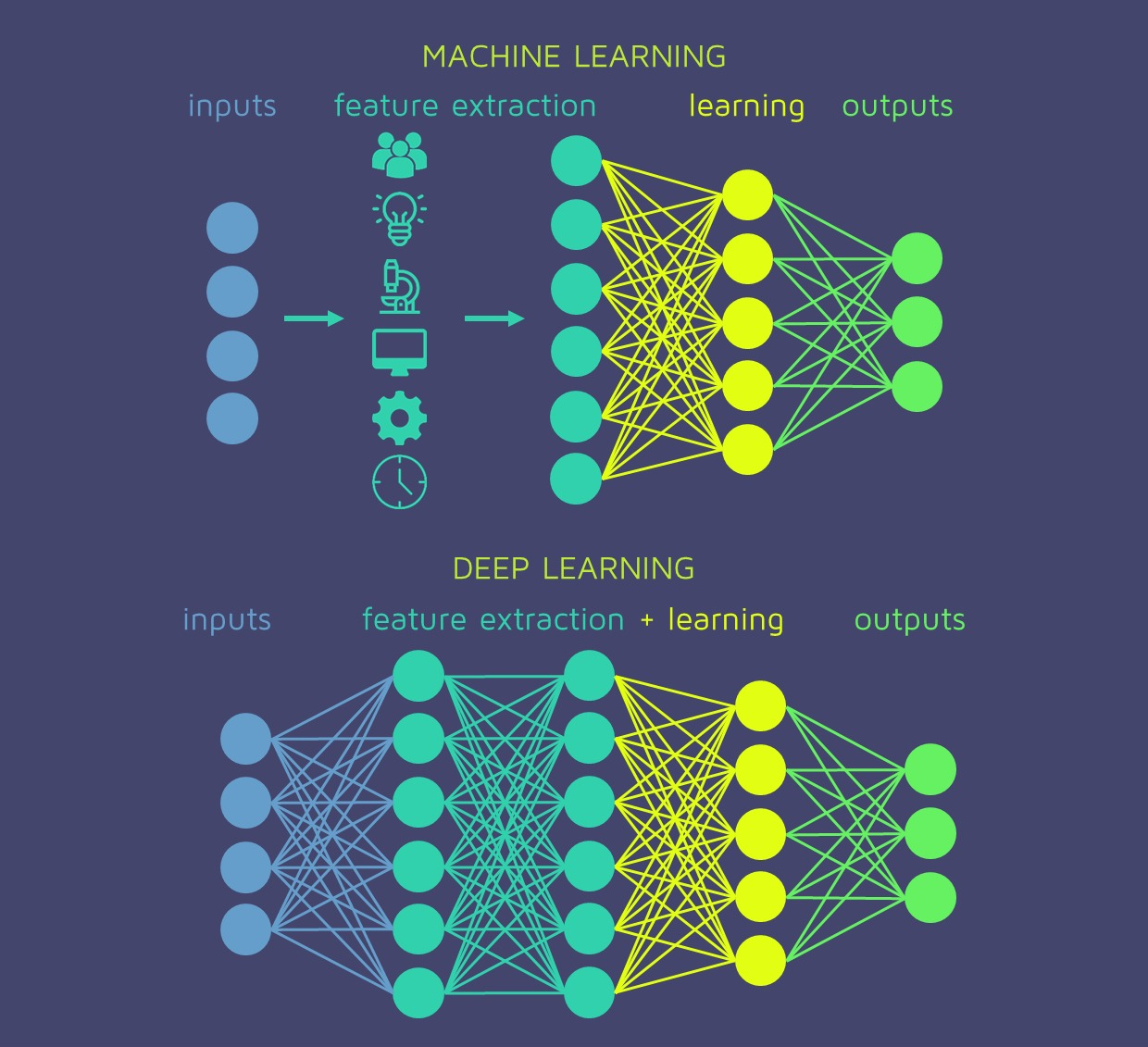
- Neural networks are a series of algorithms that mimic the operations of a human brain to recognize relationships between vast amounts of data.
- They are used in a variety of applications in financial services, from forecasting and marketing research to fraud detection and risk assessment.
- Use of neural networks for stock market price prediction varies.
- Its internal functioning (adversary, etc.)
- What kind of data does it work with (images, text, sound)
- What task you want to automate (image: labeling content or generate images)
- Different sepcific models of the same type of network (Inception, VGG16, Alexnet)
Global architecture capable of self-configuration from examples. There are different types of nets depending on:
Datasets
Datasets are sample data to provide to the network. Its evaluation criteria is qualitative (homogeneity and heterogeneity), quantitative (large amounts of data are needed), and biases (what is present in the dataset will also be in the results). After a big enough dataset is reached, the neural network goes through a "training" which is a self-configuration process of the nerwork based on the dataset.
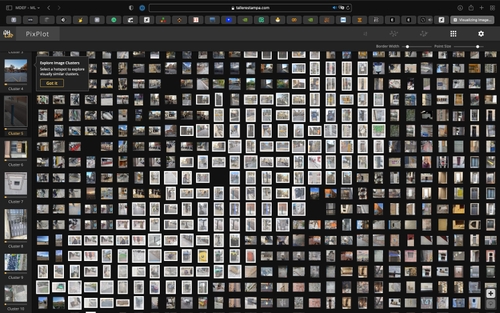
As an exercise, each person in the class was assigned to upload 100 photos from our phones and 100 photos from old and new Poblenou which would serve as a dataset for a neural network that would a map classification of the photos. The resulting map was a 2D/3D map which clustered the photos on their colours, their geometric shapes, or their faces and landscapes.

Training a Neural Network
All Neurons in a layer generate an Output, however their weights are not the same for the next Neurons Layer. This means that if a Neuron on a layer notices a particular pattern, it may have a lower impact on the entire picture and may be partially or fully muffled. This is known as weighting: a large weight indicates that the input is significant, whereas a lower weight indicates that it should be ignored. Every neuron-to-neuron connection will have a weight associated with it.
And this is how Neural Network Adaptability works: Weights will be modified during the workout to meet the goals we've set (recognising that a person is a person and that an oven is an oven). To put it plainly: Training a Neural Network entails determining the proper Weights of the Neural Connections thanks to a feedback loop known as Gradient Backward Propagation.

AI Biases
The underlying prejudice in data used to construct AI algorithms is known as AI bias, and it can lead to discrimination and other social effects. It is very difficult to create non-biased algorithms, since these algorithms are created by humans that could leak some their own biases into the system willingly or not.
The data that is used should represent what "should be" and not what currently is. Randomly sampled data will inherently have biases since we live in a biased world. In one such case, Amazon used an algorithm for hiring employees which was later found to be biased against women. For its datasets, Amazon used the resumes submitted during the past 10 years, and since most of these applications were made by men, it was trained to favour men over women.
What this could mean is that there should be some sort of data governance which would include an evaluation by different social groups. With such new and potentially revolutionary technology, we have an obligation to regulate modeling processes to ensure that they are used ethically. In a similar manner to how there are regulations in the field of Biology against biological weapons, so too should artificial intelligence have regulation to prevent an even bigger divide in our society.
Project
Our project this week was to ideate a prototype utilising artificial intelligence. Our group created a personal health assistant called "Freud(e)" which is a set of wearables and a “robot” interface that analyzes data from one's body, environment, and social life. It aids in understand the possible reasons of one's current state and demonstrates opportunities to feel better.
Below you may find our group's final presentation: